

Terminology
- Cluster: A cluster is composed of one or more Tensorflow servers, called tasks.
- Job: a group of tasks that have a common roal. For instance, parameters server, worker server.
- Task: A task corresponds to a specific TensorFlow server, and typically corresponds to a single process. A task belongs to a particular “job” and is identified by its index within that job’s list of tasks.
Table of Contents
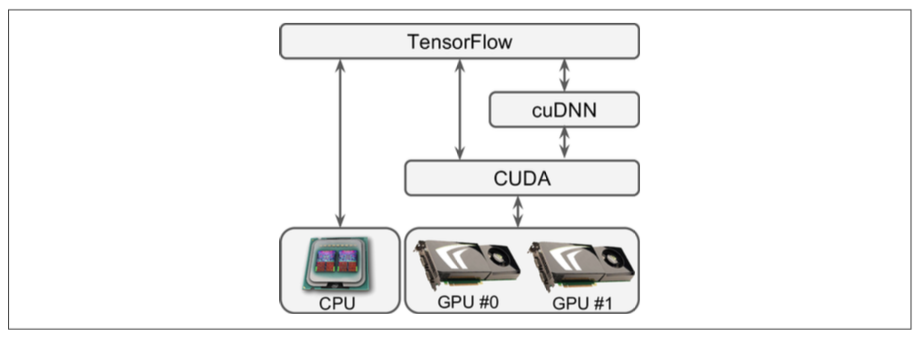
Multiple Devices on a Single Machine
Dependencies:
- CUDA: Nvidia’s Compute Unified Device Architecture Library allows developers to call GPUs
- cuDNN: CUDA deep neural network library to call CUDA
- tensorflow-gpu
Managing GPU RAM
By default Tensorflow will grab all the RAM in all available GPUs the first time you run a graph, so if you run a second Tensorflow program, Memory error showing up.
- One solution is to run each process on different GPU card.
# run script in specific GPU card
CUDA_VISIBLE_DEVICES = 0,1 python3 program.py
- Another option is to set a threshold for Tensorflow, which limits the program can only grab a fraction of GPUs’ memory.
config = tf.ConfigProto()
config.gpu_option.per_process_gpu_memory_fraction = 0.4
session = tf.Session(config=config)
Placing operations on Devices
Using the following code to place operation to a specific device, otherwise it will place to the default device.
Cautions: there is no way to pin nodes on a specific CPUs or a subset CPUS
with tf.device("/cpu:0"):
a = tf.Variable(3.0)
Multiple Devices Across Multiple Servers
- Create a Clusesr
cluser_spec = tf.train.ClusterSpec({
"worker": [
"machine-a.example.com:2222", #/job:worker/task:0
"machine-b.example.com:2222" #/job:worker/task:1
],
"ps": [
"machine-a.example.com:2221", #/job:ps/task:0
]})
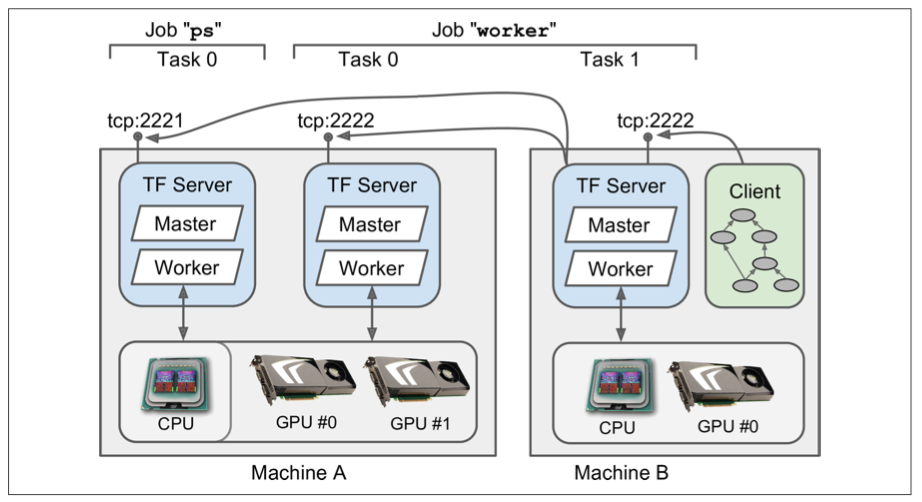
- Run a server
server = tf.train.Server(cluster_spec, job_name="worker",task_index=0)
# start first worker task
- Use
server.join()to wait servers finish
In distribution tensorflow, variables maintain by resource container. In other words, we can access the variable across different sessions and servers. To avoid name clash, we can wrap variables by using
tf.variable_scopeortf.container.tf.containeris easy to reset and release variables.Advantages:
- Be able to explore a much larger hyperparameter space when fine-tuning your model
- Large ensembles of NN efficiently
Parallelizing Neural Network on a Tensorflow Cluster
One Neural Network per device
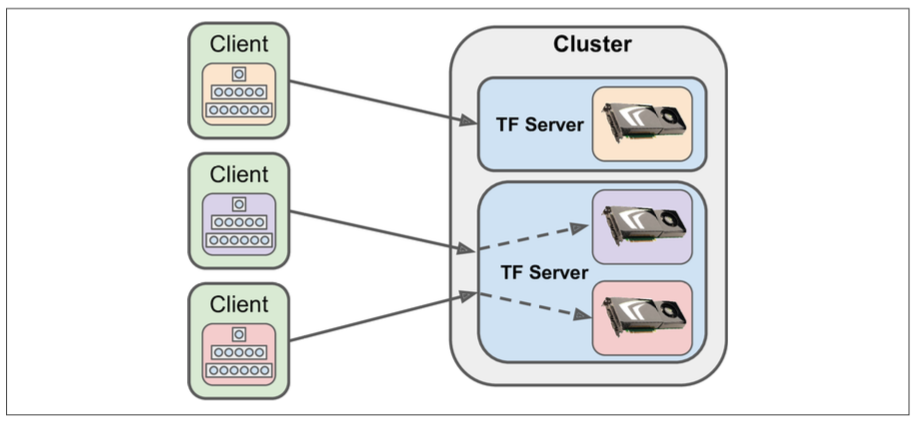
One client per neural network per device.Each device running similar neural network with different hyperparameters.This solution is perfect for hyperparameter tuning.
In-Graph Versus Between-Graph Replication (ensemble)
- In-Graph: one client,one graph, one session maintains all stuff, one neural network per device.
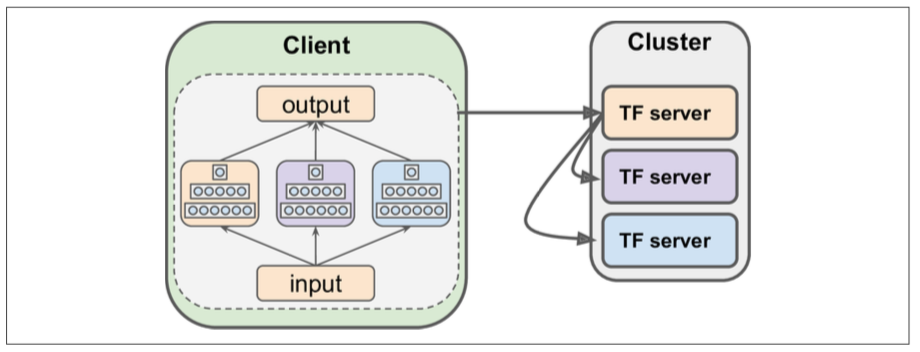
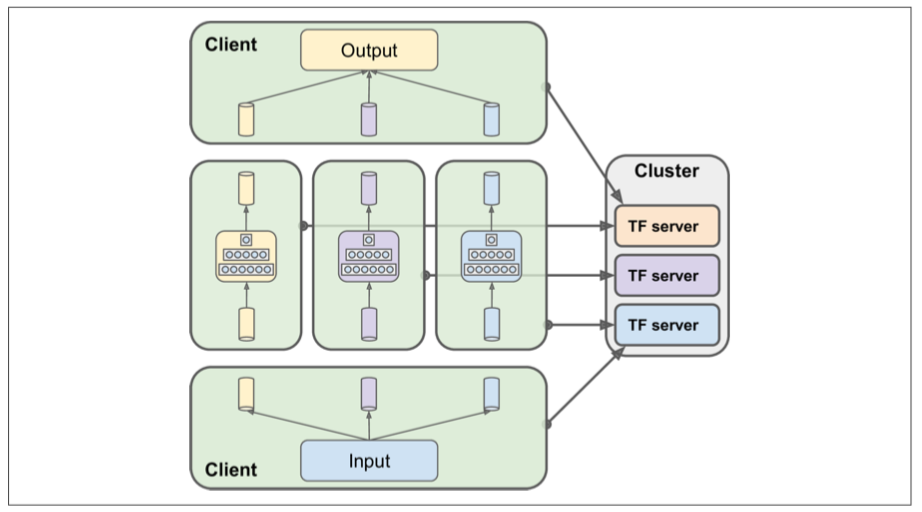
- Between-Graph: several clients maintain
Input,OutputandNeural Network. Each Neural network is an individual graph.
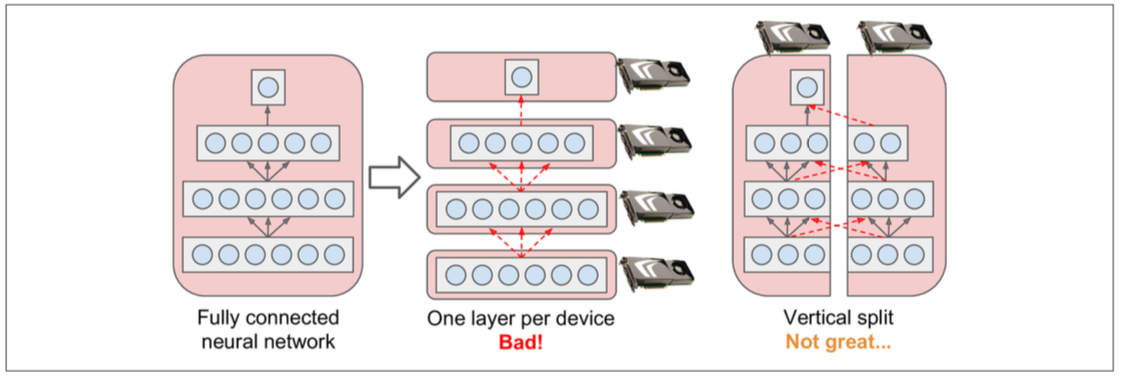
Model Parallelism
- Separate Neural network Horizontally or Vertically.
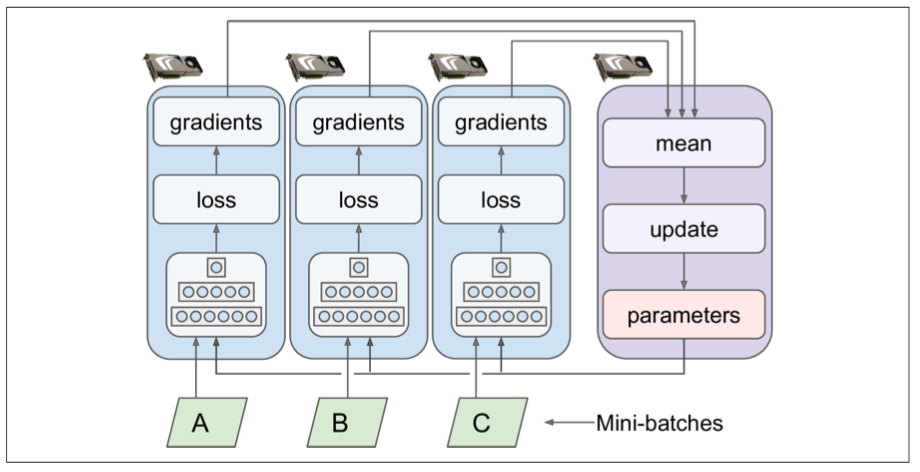
Data Parallelism
- Each device running same neural network, but feeded different mini-batch data. For each iteration, neural network fetch parameters from
PS, then Gradients from each network aggrated to update parameters inPS. There are two main approach, synchronous and asynchronous. - With synchronous updates, the aggregator waits for all gradients to be available before computing the average and applying the result.The downside is faster replica have to wait slower one at every iteration. To make it more efficient, we can update parameters only if a fraction of replicas has finished.
- With asynchronous updates, whenever a replica has finished computing the gradients, it immediately uses them to update the model parameters.
Reference:
- Distributed Tensorflow: Tensorflow official doc
- Echosystem: tensorflow official github project, a integration of tensorflow with other open-source framework
- Hands-on Machine Learning with Scikit_Learn & Tensorflow: Chapter 12, Distributing Tensorflow Across Devices and Server